Bartz v. Anthropic Fairness Hearing: Final Reminder, 91.3% Claims Rate, and updates from the Docket May 14, 2026 By Authors Alliance
Authors Alliance Backs Illinois HB5236 and the Broader State Ebook Licensing Effort May 12, 2026 By Dave Hansen
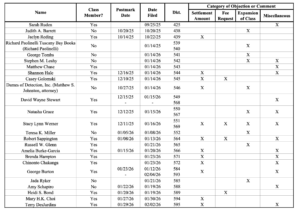
Bartz v. Anthropic Settlement Update: New Date and Time for the Fairness Hearing (you can join online) and Unsealed Objections April 14, 2026 By Authors Alliance