

“We say that a model has “memorized” a piece of training data when (1) it is possible to reconstruct from the model (2) a (near-)exact copy of (3) a substantial portion of (4) that specific piece of training data. We distinguish memorization from “extraction” (in which a user intentionally causes a model to generate a (near-)exact copy), from “regurgitation” (in which a model generates a (near-)exact copy, regardless of the user’s intentions), and from “reconstruction” (in which the (near-)exact copy can be obtained from the model by any means, not necessarily the ordinary generation process).” A. Feder Cooper and James Grimmelmann, The Files are in the Computer: On Copyright, Memorization, and Generative AI (2025)
The above quote is from a fairly recent essay on the topic of Generative AI and memorization. It’s worth a thoughtful read, as are many of the articles written by or in collaboration with Cooper and Grimmelmann (see also Talkin’ ‘Bout AI Generation). They go into far more detail and depth on the topic of memorization than I can, though hopefully what I write here will be a useful entrypoint for some readers. As they note in their introduction, they are not taking positions on this technology and instead seek to describe it with accuracy (“We seek clarity, precision, and technical accuracy”, Cooper and Grimmelmann at 147).
Unlike them, I plan on taking some positions. Memorization is having a moment in the news, with grand pronouncements about its implications for the growing number of AI copyright suits: “Large language models don’t “learn”—they copy. And that could change everything for the tech industry.”
While Cooper and Grimmelmann are making every effort to not take a position on memorization, it is certain that memorization is already playing a meaningful role in current AI litigation, will likely inform future litigation related to outputs (e.g., substantially similar infringing outputs or infringement based on memorized inputs), and is being raised as a specter to question whether the technology itself can be a fair use. In this post, I am most interested in taking on the question of whether memorization forecloses the possibility of this technology as a fair use.

Memorization as inherent vice
To be absolutely clear, memorization happens in all models. As Cooper and Grimmelmann put it: “all generative-AI models memorize some portion of their training data.” (Cooper and Grimmelmann at 157). As a user of the models, especially the image generation models, it’s not hard to find examples of memorization. Below are three examples of Leonardo da Vinci’s Mona Lisa, one from Wikipedia, one generated by Google’s Gemini (2 prompts: “generate an image of da Vinci’s Mona Lisa”; “just the painting please”), and one generated by OpenAI’s ChatGPT (prompt: “generate an image of da Vinci’s Mona Lisa”). Without information to the contrary, I will presume that the generated images are products of memorization of Mona Lisa in the training data, and that this particular instance of memorization has been permitted by the AI companies, possibly facilitated and enhanced through training and not filtered at the output stage by guardrails due to the Mona Lisa’s public domain status.
(Note: I use the Mona Lisa because the demonstration is uncontroversial and clear, but memorization can be found with other, in-copyright works.)
Memorization is important to would-be plaintiffs because, it may be argued, memorization helps establish the elements of a copyright infringement claim. ”To establish infringement, two elements must be proven: (1) ownership of a valid copyright, and (2) copying of constituent elements of the work that are original.” (Feist Publications, Inc. v. Rural Telephone Service Co., 499 U.S. 340, 361 (1991))
Memorization in AI models is also of particular interest to those suing AI companies if it can move the needle on the fair use analysis. Of particular interest is how it may affect the fourth factor fair use analysis, which focuses on the effect of the use on the potential market for or value of the original copyrighted work. For example, if a model would allow you to read or view the entirety of an in-copyright work, then it can be easier to argue that it is serving as a market substitute for that work, which is often a central consideration in any fair use claim.
As we’ve noted in previous posts, even in the absence of evidence that outputs are substantially similar to input texts used for training, we’ve seen the market dilution concern in Kadrey v. Meta, where Judge Chhabria wrote:
“As for the potentially winning argument—that Meta has copied their works to create a product that will likely flood the market with similar works, causing market dilution—the plaintiffs barely give this issue lip service, and they present no evidence about how the current or expected outputs from Meta’s models would dilute the market for their own works.” (Kadrey v. Meta opinion at 4). (This is a novel theory and one that has been deservedly questioned – see Ed Lee’s Copyright Dilution Under Constitutional Scrutiny)
To address the absence of evidence raised in Kadrey, we are now seeing moves towards surfacing potential market harms based on memorization. In Alignment Whack-a-Mole : Finetuning Activates Verbatim Recall of Copyrighted Books in Large Language Models, the article authors detail their efforts to extract text from frontier LLMs, using a finetuning approach that, according to their research, enhances their ability to extract blocks of text from books used to train the models. (“In the within-author setting—finetuning and testing on books by the same author—we find that finetuning unlocks latent memorization, enabling all three models to regurgitate massive amounts of verbatim text from held-out books, in some cases reproducing as much as 60% of an entire book. More alarming, this effect generalizes cross-author: training exclusively on Haruki Murakami’s books enables substantial extraction from over 30 other authors regardless of genre—in some cases reproducing over 80% of a book’s verbatim content, with single regurgitated stretches exceeding 460 words.”) (Alignment Whack-a-Mole at 3)
The article authors make the connection between their research and ongoing litigation explicit:
“There is another kind of market harm, not at issue in those cases, but which the present study may bring to the fore. A key factor in Bartz and Kadrey was the absence of evidence that the models trained on copied works generated outputs that reproduced the source works. But what if the outputs did reproduce the source works? What if users, with little effort, could extract substantial portions of the source works? The “regurgitations” are verbatim, or highly similar, copies that could well substitute for the source works. For example, why comply with a paywall, when one can prompt an AI system to deliver the content unencumbered by access or use restrictions? Would the AI developers’ failure to secure their systems against regurgitation-generating prompting undermine their defense on the fourth fair use factor?” (Alignment Whack-a-Mole at 11)
As a brief departure from this discussion of memorization, I’d like to also note that two of the authors of the Whack-a-Mole article, Tuhin Chakrabarty and Jane C. Ginsburg, also collaborated on another article, Readers Prefer Outputs of AI Trained on Copyrighted Books over Expert Human Writers, which looked at reader preferences and found statistically significant reader preferences for finetuned AI-generated works. Again, the authors concluded that their findings held significance for fourth factor fair use analysis.
There is clearly interest in memorization related fourth-factor evidence, and the pairing of Whack-a-Mole with Readers Prefer Outputs are two of the clearest examples of this I’ve been able to find. The animating force behind these inquiries, and the great consequence of memorization for these authors, is to make the case that AI models may fail to qualify as fair use because they offer impermissible competition with originals under the fourth fair use factor. The argument is that this happens through the profoundly negative impact AI has on the markets for and value of in copyright works, whether it is because the models risk reproducing too much of the in copyright works or because we ultimately prefer the outputs of the models.
[Below, I will offer a fuller counter to this view of the world. For those who prefer not to wait, I will offer a preview: memorization should be embraced rather than suppressed. The more, and more diverse, the material models retain, the more users can do with them. Paired with strong protections for users, this approach avoids two failures at once. AI neither overcorrects by foreclosing legitimate uses nor gets defined solely by commercial interests.]
Where do we draw our lines?
In both the Cooper and Grimmelmann essay and the Whack-a-Mole article, the authors nod to prior fair use litigation, which found that reproductions of limited portions of in-copyright works did not preclude fair use (see Authors Guild v. Google Inc., 804 F.3d 202 (2d Cir.), 2015). It’s hard to not think of Google’s “snippet views” when considering memorization and the portions of in-copyright works that the Whack-a-Mole authors point to as potentially winning evidence of market harm. While the Whack-a-Mole authors make efforts to show that the memorized portions of in copyright works potentially present a far more serious threat and that AI model users might attempt to recreate whole portions of in-copyright works, I am ultimately left feeling that this is the same rhetoric that we see each time a new technology promises large scale disruption.
Earlier in this post, I said that I would take some positions. Here are the positions I’d like to take at this time: (1) I don’t want to deny that AI models are disruptive and may ultimately do incredible harm; (2) I believe memorization will be a point of contention so long as the AI copyright lawsuits continue to wind their way through the legal system; (3) With some caveats, I think that overstating the threats from memorization is the wrong approach to contending with the potential harms (economic and otherwise) presented by AI and may ultimately be a strong disservice to the public interest.
Position 1
My first position is hard to argue with. It’s abundantly clear that virtually everyone is concerned about AI, its potential for monumental disruption, and the need to find solutions to its capabilities. OpenAI recently released Industrial Policy for the Intelligence Age: Ideas to Keep People First, which grapples with the social implications of AI and that these technologies could wreak enormous havoc on the economy and livelihoods of people everywhere (though in a way that one critic called “hazily sketched” and “reads a lot like something that ChatGPT would spit out, if you asked it to research ideas for combating AI-induced inequality for 10 minutes.”) Anthropic recently developed Claude Mythos and has limited its release due to substantial concerns around cybersecurity threats it could facilitate (See also Project Glasswing). These concerns, well documented, seem credible.
Below is a sampling of ongoing litigation related to AI. The technology is touching many facets of our lives; coupled with the rapidity and sometimes carelessness of its expansion, we are seeing a recipe for many types of harm.
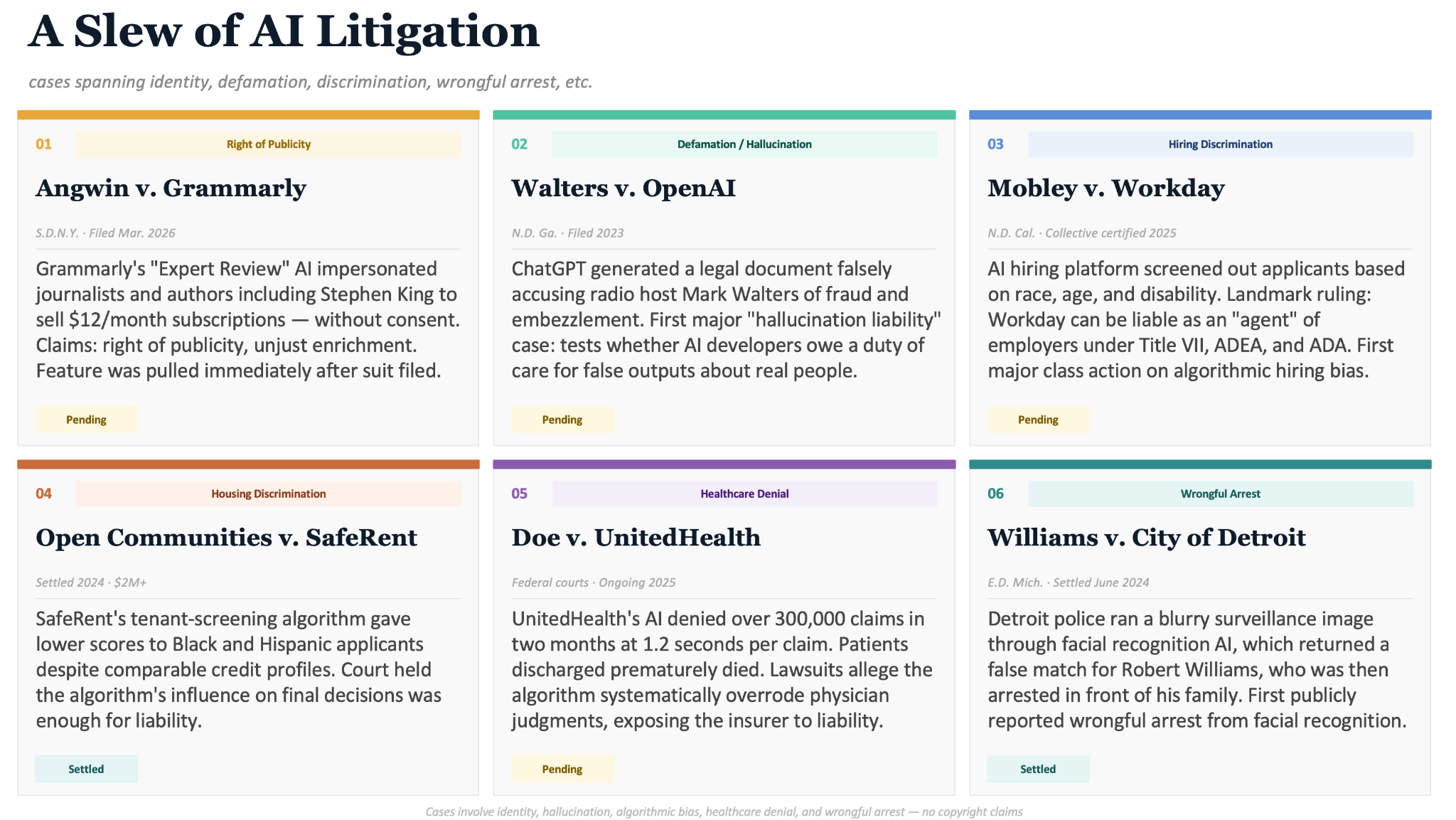
I could go on with lists, databases, and articles and reports. The boom in AI over the past several years has been well documented, examined, and has created a simultaneous boom in commentary. If I tried to argue that AI is not likely to be disruptive and cannot, will not, cause damage, I think you’d have to extract my head from the sand.
Position 2
There are now roughly 100 copyright lawsuits against AI companies in the United States. That number will grow. Unless there are clear signs that it is not a winning strategy, we will see variations of memorization raised in more suits. Some litigation where memorization has already played a prominent role:
- If you look at the original complaint in The New York Times Company v. Microsoft, memorization is a key part of the factual allegations: “GPT-4 copied this content and can recite large portions of it verbatim…these examples represent a small fraction of Times Works whose expressive contents have been substantially encoded within the parameters of the GPT series of LLMs. Each of those LLMs thus embodies many unauthorized copies or derivatives of Times Works.” (Complaint at 31-32)
- In their motion for partial summary judgment, the plaintiffs in Concord Music Group v. Anthropic emphasized the role of memorization: “During training, Anthropic endeavored for its AI models to “memorize” Publishers’ lyrics so the models would output those lyrics. An internal Anthropic report recognized that AI models like Claude “memorize A LOT, like a LOT.””(Motion at 14).
- In Copyright’s Jagged Frontier, Matthew Sag details both lawsuits based on character memorization, such as Disney v. Midjourney (“It included dozens of clearly recognizable pictures of Princess Elsa, Bart Simpson, Darth Vader, The Mandalorian, Baby Yoda, Shrek, the Minions, and more.”) and other instances where models like OpenAI’s Sora2 produced images of characters like Snoopy and Pikachu (Jagged Frontier at 31).
For those of you interested in a deeper dive into this topic, Sag’s article is a worthwhile read. Not only does he provide a fuller picture of instances of memorization, he also helps to drive home a point that is made elsewhere: memorization is a product of model learning and we will often see the memorization of a block of text from a novel, or a beloved character, in the way we will see the useful and desirable byproducts of model training. “Memorization presents a stubborn technical challenge because most attempts to meaningfully curb the retention of copyrightable expression would also blunt a model’s capacity to learn a wide range of useful and unobjectionable material.” (Jagged Frontier at 29)
Given that the perils of memorization are intimately tied up with the benefits of AI models, it is hard to imagine that we will see instances of memorization go away completely. It seems far more likely that we’ll see swiss cheese AI models, holes where all of the most pernicious/litigation provoking (for users and the AI companies themselves) memorization has been excised or guardrailed unless licenses can be obtained. Tens of thousands of little line drawing exercises, ever evolving, likely fairly opaque to individual users, a writhing, pulsing, beautiful and ugly mess.
Position 3
At a high level, I want to first address those who suggest that memorization is likely to yield problems for defendants in the fourth factor fair use analysis. Returning briefly to Alignment Whack-a-Mole, the authors of the article suggest that, so long as memorization takes place in the models, it could weaken the fair use defense of those models (“As the court acknowledged, no matter how “transformative” the use, if its implementation depends on inadequately secured copies, the threat to the copyright owner’s market could offset the transformativeness.”) (Whack-a-Mole at 12) (internal citation omitted).1
A regurgitated passage without the surrounding work isn’t competing in the same market as the book. The Authors Guild v. Google court understood this; the snippet view one sees in Google Books doesn’t substitute for the book. The reproduction of limited passages of books is also not a bar to fair use. If you spend enough time looking at digital collections and online archives, if you spend enough time thinking about copyright, you will see examples of fair use and entire in-copyright works everywhere. In Bill Graham Archives v. Dorling Kindersley Ltd, whole Grateful Dead posters were reproduced as historical artifacts within a cultural history book; the court found that this was a fair use. Authors Guild, Inc. v. HathiTrust – entire books used to create, among other fair uses, a searchable digital archive – again, a fair use. Kelly v. Arriba Soft Corp. – full images in thumbnail form – the foundation for image search that we rely on today – fair use. Ordinary, pro-social uses that have never been litigated such as (to pick one example) New York Philharmonic Digital Archives provides access to a range of works, some still in copyright and yet available in their entirety.
Of course, I know that we will have to draw lines and that harder cases are on the horizon. To spin up just one example inspired from Sag’s Jagged Frontier article, what happens when a user of one of the models tasks an agent with publishing a daily online comic strip, with millions of readers, featuring the travails of Detective Snoopy and his trusty sidekick, Pikachu?

Detective Snoopy and Pikachu comic generated using Google’s Gemini
Today, such scenarios are both easy to imagine and execute. In the future Sag realistically imagines, these scenarios will be addressed by some combination of guardrails and licensing regimes. Sometimes a guardrail will prevent a given use categorically. For the vast majority of uses, he sees a version of Content ID for AI, one where users have greater freedom of expression against a backdrop of negotiated licenses. “Licensing the rights to turn off targeted copyright safety measures and allow end users a freedom of expression that would otherwise cross over into copyright infringement has the potential to be a billion-dollar industry.” (Copyright’s Jagged Frontier at 10).
Sag’s account is probably correct as a prediction. The question is whether it should also be accepted as a prescription. Professor Katrina Geddes’s Engineering Semiotic Democracy is the strongest articulation I’ve found of an alternative view, not necessarily because it’s where things are heading, but because it helps show what can be lost if we let memorization-anxiety drive us to a licensing-mediated default.
AI is going to allow a lot of people who could not participate in cultural production to read, write, make images, and reach audiences in ways that were unfathomable previously. Geddes calls this phenomenon “Semiotic Democracy”—“When every member of a socio-political community has a roughly equal capacity to contribute to, participate in, and shape their cultural life, I refer to this as “semiotic democracy.” (Semiotic Democracy at 35)
If we can create space where you and I can make things, ambitious things, small things, things that sometimes liberally draw on what has come before, without being immediately told no and without the constant fear that we will be sued into bankruptcy the moment we engage in that act of creation, we will have the ability to shape our creative lives differently. If our laws and norms give us a sphere of protection around our personal uses, in a way roughly equivalent to sketching in a private notebook (even if that notebook is built by a large corporation), a greater percentage of people will express themselves and explore the world more fluidly than they would otherwise.
If we can create space where you and I can make things, ambitious things, small things, things that sometimes liberally draw on what has come before, without being immediately told no and without the constant fear that we will be sued into bankruptcy the moment we engage in that act of creation, we will have the ability to shape our creative lives differently. If our laws and norms give us a sphere of protection around our personal uses, in a way roughly equivalent to sketching in a private notebook (even if that notebook is built by a large corporation), a greater percentage of people will express themselves and explore the world more fluidly than they would otherwise.
In Sag’s vision of the future (again, probably a realistic view), memorization leads to guardrails and licensing deals, where we will be told no when a given use seems too risky and a negotiated solution cannot be secured. We will be told yes, probably with caveats, when big moneyed players can forge a path forward. As users, our sense of the possible will be shaped by corporate interests that will often be misaligned with our own.
In the version of the future raised by Geddes, memorization is not something to run away from. The more the models memorize, and the greater the breadth and diversity of the materials on which they are trained, the more users will be able to do with them, and the richer the tools will become. Coupled with robust protections for private, non-commercial use (uses that an individual makes for themselves, their family, or their close friends), AI technologies will not fall into the trap of overcorrecting and blocking legitimate uses, nor be defined and dictated exclusively by commercial interests.
To be clear, the Detective Snoopy case above is easy in both Sag’s and Geddes’s worlds. It’s commercial, public-facing, and substitutional, and it loses. The interesting cases are the ones in between, and that’s where the choice of framework matters: a licensing regime defaults to permission, a personal-use sphere defaults to freedom, where programmers can pursue open source AI projects and authors can use those AI models to experiment with new forms of expression.
What we lose if we accept the framing that says any memorization weighs dispositively against fair use is greater than what we lose to memorization itself. We lose the possibility of a sphere where individuals can read, write, draw, and play with these tools without first negotiating a license. We lose the version of this technology that lets more people participate more fully in cultural life, not fewer. Our works are in the models. We should let them be in the models. Not everybody will get precisely what they want and it can still be fair.
- The analysis here is focused on US law. Please note that the Whack-a- Mole paper makes assertions about the importance of memorization in other jurisdictions that may well prove to be correct. ↩︎
Discover more from Authors Alliance
Subscribe to get the latest posts sent to your email.